
This is another ESRI Online Training Course
Problem:
Spatial statistics is the analysis of characteristics of data across space. Looking at data is a good start, however, it is hard to visually spot patterns. Spatial statistics techniques to help you identify and answer questions about those spatial patterns and relationships in the data. The objective is to look at the European weather stations to determine when freeze warnings are needed, and how these stations are related to each other. The basic premise of spatial statistics are that locations that are geographically close to one another will have similar traits, unlike those that are further away.
Analysis Procedures:
A flow diagram of the spatial statistics is found in Figure 1.
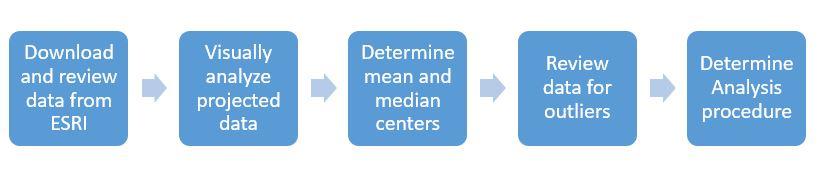
Figure 1: Flow diagram for the exploration of data patterns.
Then the mean center as well as the median center are determined, and if these locations were near one another then the data would be equally distributed. The Mean Center tool creates a feature class displaying the average location of your dataset based on each point’s x,y location. The the median center is the middle location. This is calculated by ordering the x and y values for each of your locations and then picking the middle value from the list. To see if any directional trends are apparent, the directional distribution can be calculated (Figure 2).
The data must be analyzed as well. This includes examining the high and low values, and the range of values. This showed a potential outlier where the gap in temperature is abnormally large. This outlier can be seen in the histogram where there is a value that is not in the Gaussian curve. The QQ plot can also be used to see the outliers, these are points that stray away from the reference line. So, the abnormal temperature, which was nothing like other nearby values, which can be removed from analysis.
After removal of the outlier, the temperature data represented a normal distribution, it was time to check for stationarity. Stationarity addresses whether the locations in the dataset are related to each other based on the distance apart. This includes the creation of a voronoi map was displayed to determine the variation in the data. The data was determined to be stationary.
The Semivariogram tool determines if there are large differences between any particular points and the points that were close to it. By using this tool, the same station mentioned above is a potential outlier.
Finally, the Trend Analysis tool was used to find patterns in the data. The trend analysis tool allowes the examination of different trend lines, and how they fit to my data. In the end,A third order polynomial was the best fit for the weather station data, and that the best method for analysis would be geostatistical interpolation.
Results:
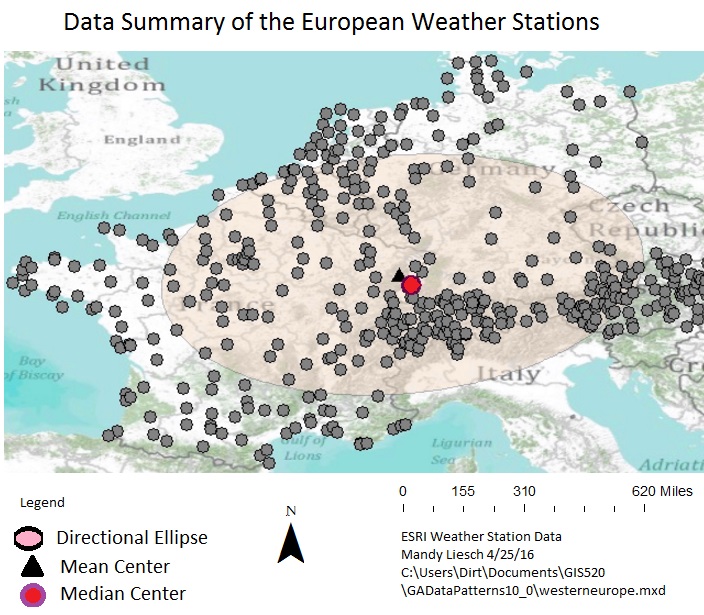
Figure 2: The mean and median center, as well as the ellipse of data orientation.
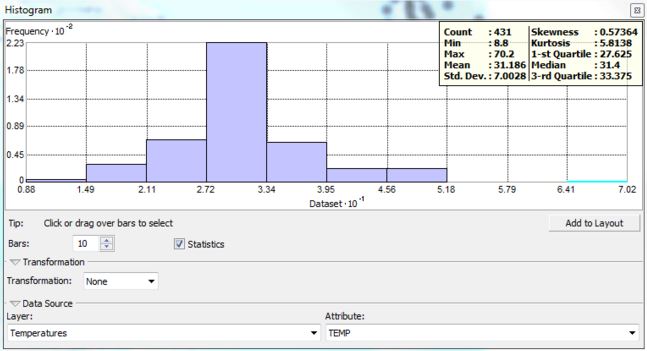
Figure 3: Histogram Analysis of the potential outlier.
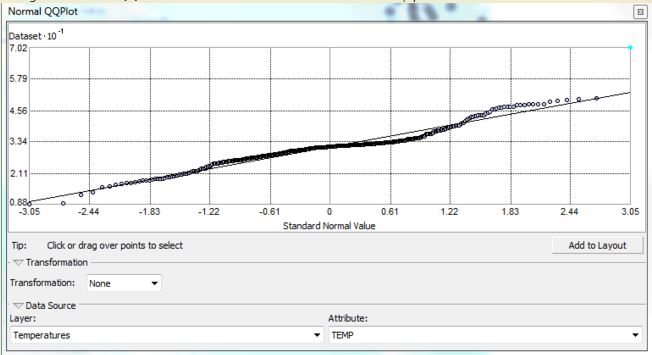
Figure 4: Normalized QQ Plot of the data

Figure 5: Voronoi histogram showing the stationarity of the data.
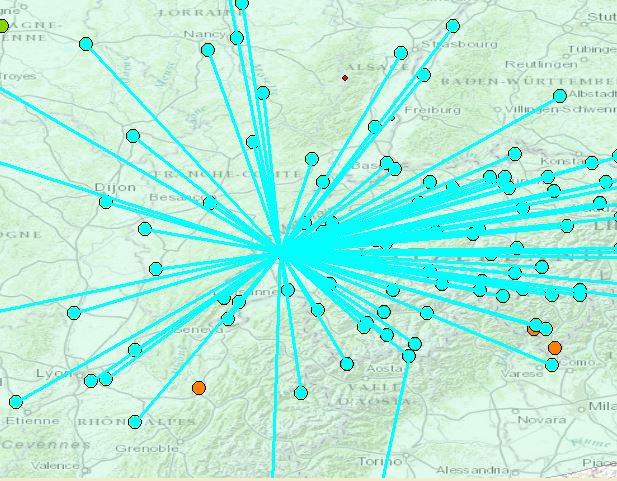
Figure 6: Visualization of the outlier by the semivariogram.
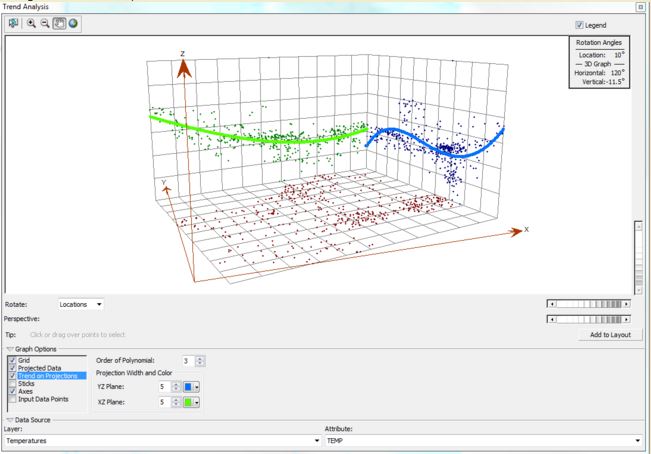
Figure 7: Trend analysis for the data showing the third order polynomial.
Application & Reflection:
Problem description: This geostatistical analysis package is one of the most useful ways to start analysis and processing of any geostatistical data. Finding outliers, determining if the data is stationary, and graphing normalized QQ plots provide the first steps in finding trends. One the outliers are removed, we can analyze the data for trends in making predictions. This type of modeling can be used to analyze soil moisture data and other physial properties, and determine if we an predict rainwater infiltration based on the soils potential to infiltrate water. This has the potential to help create more sophisticated stormwater flow and management models.
Data needed: Soil infiltration potential, either measured, or based on soil polygons from the NRCS website, and topography.
Analysis procedures: Once we gather the infiltration information for a given construction site, we can check the infiltration data for normality using the QQ plots and histograms. We can then use the trend analysis to figure out the spatial relationship of infitration, and how that relates to topography.
certificate of completion
